42. 接雨水
遍历每一个柱子,向左向右找到最高的柱子,然后取左右最高柱子中较小的那个,减去当前柱子的高度,就是当前柱子能接的雨水。
优化点:找最高柱子的过程可以优化,用空间换时间。
如果用数组来存储这个数据,需要O(n)的空间,但是观察可以发现,每个位置的数据只用了一次,而不同位置的数字之间也存在着某种联系。
所以可以使用双指针来优化,一个指向左边最高的柱子,一个指向右边最高的柱子,然后向中间移动,直到两指针相遇,此时两指针所指的柱子就是最高的柱子。在这个移动的过程中,边移动边计算当前位置能接的雨水。这样可以将空间复杂度降低到O(1)。
24. 两两交换链表中的节点
一个链表,交换相邻的两个节点,直到没有相邻的两个节点可以交换。
思路:从头到尾,每两个为一组(不足两个的不用交换),步长为2,遍历链表,使用临时变量保存当前节点的下一个节点,然后交换当前节点和下一个节点的指针,然后移动到下一个节点的下一个节点。
要注意使用last 来更新最后一个交换的节点,否则会出现链表断裂。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| while(cur!=null && cur.next!=null) {
if(first!=1)last.next=cur.next;
else first=0;
last = cur;
temp=cur.next.next;
cur.next.next = cur;
cur.next=temp;
cur = cur.next;
}
|
指针交换如下图所示:
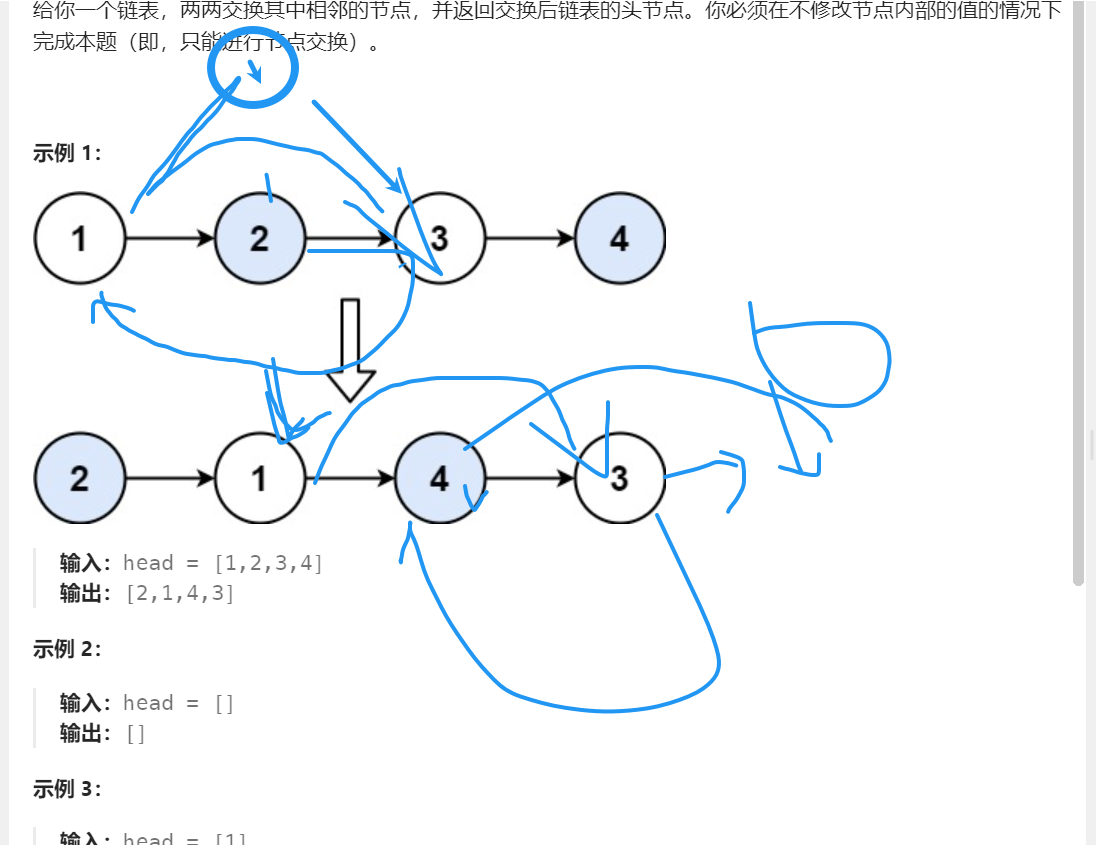 指针交换
指针交换
51. N 皇后
N皇后,不能再经典的回溯题,逻辑很好理解,即使用回溯的方式枚举所有的可能,然后判断可行性,得到所有的可行解。
不过这个输出格式实在是想吐槽,莫名其妙的格式(不过应该是我对字符串以及组织不熟悉)。
1
2
3
4
5
6
7
8
9
10
11
12
| for(int i=0;i<n;i++) {
if(c[i]==0 && x[i+num]==0 && xx[i-num+n-1]==0) {
c[i]=1;
x[i+num]=1;
xx[i-num+n-1]=1;
ans[num]=i;
f(ans,num+1);
c[i]=0;
x[i+num]=0;
xx[i-num+n-1]=0;
}
}
|
题目中要求的 字符串格式
1
2
3
4
5
6
7
8
9
10
11
|
if(num==n){
List<String> temp=new ArrayList<>();
for(int i=0;i<n;i++) {
char[] row = new char[n];
Arrays.fill(row, '.');
row[ans[i]] = 'Q';
temp.add(new String(row));
}
list.add(temp);
}
|
98. 验证二叉搜索树
1.中序遍历
排序二叉树的中序遍历是升序的。
所以可以将中序遍历输出到一个数组,再检查数组是否是升序的即可。
可以对其进行空间优化。遍历中进行判断,记录上一个节点的值,如果当前节点的值小于等于上一个节点的值,则不是二叉搜索树。
但是第一个点不是很好判断,如果设置一个初始值last=Long.MIN_VALUE, 可以解决这个问题。
也可以用一个组合节点来判断,如果是第一个就跳过。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| class Solution {
long last = 0;
public boolean isbigger = true;
public boolean first = true;
public boolean isValidBST(TreeNode root) {
if(root==null)return true;
boolean l = isValidBST(root.left);
if(first){first = false;}
else isbigger = isbigger && root.val > last;
last = root.val;
boolean r = isValidBST(root.right);
return isbigger;
}
}
|
2.递归检查
递归检查,设置上下限,递归检查左右子树。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| class Solution {
public boolean isValidBST(TreeNode root) {
"""
注意这里的上下限,如果是Integer.MIN_VALUE,则会导致死循环。
所以这里设置成null,表示无穷小。
其实我没有验证过,但是应该是可以的,思路是一样的。
"""
return check(root, null, null);
}
public boolean check(TreeNode root, Integer lower, Integer upper) {
if(root == null) return true;
if(lower!= null && root.val <= lower) return false;
if(upper!= null && root.val >= upper) return false;
return check(root.left, lower, root.val) && check(root.right, root.val, upper);
}
}
|
102. 二叉树的层序遍历
二叉树的遍历方式有很多种,深度优先搜索,广度优先搜索,层序遍历。深搜还可以分为前序遍历,中序遍历,后序遍历。广搜可以分为层序遍历,宽度遍历。
层序遍历就是先把根节点放入队列,然后依次弹出队列中的节点,并将其左右子节点放入队列,直到队列为空。
层次遍历和广搜的区别是,层序遍历是按层次遍历,广搜是按宽度遍历。
尽管都是使用队列,但是层次遍历会在每一层加入队列后停下一个间隔,记录一下这个层的宽度(通常是队列的大小),而广搜则是一次性将所有节点都加入队列,然后按宽度遍历。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> res = new ArrayList<>();
if(root ==null)return res;
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while(!queue.isEmpty()) {
List<Integer>list =new ArrayList<>();
int Size = queue.size();
for(int i=1;i<=Size;i++) {
TreeNode temp =queue.poll();
list.add(temp.val);
if(temp.left!=null)queue.offer(temp.left);
if(temp.right!=null)queue.offer(temp.right);
}
res.add(list);
}
return res;
}
}
|
105. 从前序与中序遍历序列构造二叉树
也是经典题,如果能明白中序遍历和前序遍历的特点,那么这道题就很简单。
递归
很显然,中序遍历的左右子树是由根节点分开的。而前序遍历的第一个节点就是根节点。前序遍历的第二个节点到倒数第二个节点就是左子树,倒数第二个节点到最后一个节点就是右子树。
所以,我们可以先找到根节点在中序遍历中的位置,然后递归地构造左右子树。
在中序遍历中寻找根节点的算法可以使用MAP,也可以使用线性查找。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| class Solution {
public TreeNode buildTree(int[] preorder, int[] inorder) {
return work(0,preorder.length,0,preorder.length,preorder,inorder);
}
public TreeNode work(int pl,int pr,int il,int ir,int[] preorder,int[] inorder) {
if(pl>=pr){
return null;
}
TreeNode res = null;
int val = preorder[pl];
for(int i=il;i<ir;i++) {
if(inorder[i]==val){
res = new TreeNode(val);
int leftsize = i - il;
res.left = work(pl+1,pl+1+leftsize,il,i,preorder,inorder);
res.right = work(pl+1+leftsize,pr,i+1,ir,preorder,inorder);
}
}
return res;
}
}
|
迭代
没看看懂这一块
215. 数组中的第K个最大元素
1.堆排序
本来我看那个数据规模,K次找最大,复杂度就是O(K * N),10^9应该能过的,结果没有,就是复杂度还不够。
标签里有堆排序,所以用堆排序来做。(很长时间没看堆排序,所以有些生疏,在更新堆的时候搞错了边界,需要注意)
堆排序的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
class Solution {
int [] heap = new int[100005];
int cur=1;
public int findKthLargest(int[] nums, int k) {
int len = nums.length;
int ans = -1;
for(int i=0;i<len;i++){
insert(nums[i]);
}
for(int i=0;i<k;i++) {
ans = deleteTop();
}
return ans;
}
void insert(int num) {
heap[cur]=num;
int tmp = cur;
boolean flag = true;
while(flag && tmp/2>=1) {
if(heap[tmp]>heap[tmp/2]) {
swap(tmp,tmp/2);
}
else {
flag = false;
}
tmp/=2;
}
cur++;
}
int deleteTop() {
int res = heap[1];
heap[1] = heap[cur-1];
cur--;
int tmp = 1;
while(tmp*2<cur && (heap[tmp]<heap[tmp*2] || heap[tmp]<heap[tmp*2+1])) {
if(heap[tmp*2]>heap[tmp*2+1]) {
swap(tmp,tmp*2);
tmp = tmp*2;
}
else {
swap(tmp,tmp*2+1);
tmp = tmp*2+1;
}
}
return res;
}
void swap(int i,int j) {
int temp =heap[i];
heap[i]=heap[j];
heap[j]=temp;
}
}
|
堆排序其实很简单,只有两个操作,插入和删除。
- 插入就往堆的末尾插入一个元素,然后从堆的最后向上更新堆。
- 删除就是删除堆顶元素,将最后一个元素放到堆顶,然后从堆顶向下更新堆。
堆是一棵顺序存储的完全二叉树。
其中每个结点的关键字都不大于其孩子结点的关键字,这样的堆为小根堆。反之,每个结点的关键字都不小于其孩子结点的关键字,这样的堆为大根堆。
实现起来很简单,就是维护一个数组和数据个数,然后每次插入和删除的时候,都更新堆。(更新的时候好像还可以使用递归的写法,以后再研究)
堆排序的时间复杂度是O(NlogN),N是数组的长度,logN是堆的高度。
对于本题,时间复杂度是O(NlogN),非常接近于O(N)。
2.快速选择算法
快排每次都选择一个元素作为基准,然后将比基准小的放左边,比基准大的放右边。按这个基准分割,左边的元素都比基准小,右边的元素都比基准大。这个基准的位置就不会变了,即最终的位置。在排序过程中,只要这个位置是第K个,就说明这个就是第K大的元素。
[TODO]
具体代码还没写,先放这。
279. 完全平方数
给你一个整数 n ,返回 和为 n 的完全平方数的最少数量 。
完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而 3 和 11 不是。
示例 1:
输入:n = 12
输出:3
解释:12 = 4 + 4 + 4
思路
最简单的思路就是枚举所有的平方数的组合,查看是否和n相等,寻找最小的组合;
但这样会很差,很多重复的判断,很多不必要的判断。
显然,可以察觉到,尽量用大的平方数进行相加,能减少数量。
所以在使用搜索的方式时,需要从大数开始枚举,通过回溯的方式,完成对组合的枚举(然后再加一些剪枝优化)
但是,很明显有重复搜索(重叠子问题),所以可以进行记忆化搜索。
同时发现,f[n]只与f[m] (m<n)有关,满足最优子结构。
可以用动态和规划,直接进行迭代。(实际上这就是一个完全背包问题)
1.直接搜索(ai)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
| import java.util.ArrayList;
import java.util.List;
class Solution {
private int minCount;
public int numSquares(int n) {
minCount = Integer.MAX_VALUE;
List<Integer> squares = new ArrayList<>();
for (int i = (int) Math.sqrt(n); i >= 1; i--) {
squares.add(i * i);
}
backtrack(squares, 0, n, 0);
return minCount;
}
private void backtrack(List<Integer> squares, int start, int remain, int count) {
if (count >= minCount) {
return;
}
if (remain == 0) {
minCount = count;
return;
}
for (int i = start; i < squares.size(); i++) {
int square = squares.get(i);
if (square > remain) {
continue;
}
backtrack(squares, i, remain - square, count + 1);
}
}
}
|
2.记忆化搜索
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| class Solution {
int[] memo;
public int numSquares(int n) {
memo = new int[n + 1];
Arrays.fill(memo, -1);
memo[0] = 0;
List<Integer> squares = new ArrayList<>();
for (int i = 1; i*i <= n; i++) squares.add(i*i);
return dfs(squares, n);
}
private int dfs(List<Integer> squares, int remain) {
if (memo[remain] != -1) return memo[remain];
int minCount = Integer.MAX_VALUE;
for (int s : squares) {
if (s > remain) continue;
int subCount = dfs(squares, remain - s);
if (subCount != Integer.MAX_VALUE) {
minCount = Math.min(minCount, subCount + 1);
}
}
memo[remain] = minCount;
return minCount;
}
}
|
3.动态规划
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| class Solution {
public int numSquares(int n) {
int[] dp = new int[n + 1];
Arrays.fill(dp, Integer.MAX_VALUE);
dp[0] = 0;
List<Integer> squares = new ArrayList<>();
for (int i = 1; i*i <= n; i++) squares.add(i*i);
for (int j = 1; j <= n; j++) {
for (int s : squares) {
if (j >= s) {
dp[j] = Math.min(dp[j], dp[j - s] + 1);
}
}
}
return dp[n];
}
}
|
这套代码的循环不太一样。具体见‘背包’中的完全背包问题
4.数学分析
奇技淫巧
根据「四平方和定理」:
任何自然数都可以表示为最多 4 个完全平方数的和。
如果 n 是 4^k*(8m+7) 形式,则必须用 4 个平方数。
否则,判断是否能由 1 个、2 个平方数组成,剩下的都是 3 个。
这种方法时间复杂度为 O(√n),远优于 DP 的 O(n√n):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| class Solution {
public int numSquares(int n) {
if (isPerfectSquare(n)) {
return 1;
}
while (n % 4 == 0) {
n /= 4;
}
if (n % 8 == 7) {
return 4;
}
int maxBase = (int) Math.sqrt(n);
for (int i = 1; i <= maxBase; i++) {
if (isPerfectSquare(n - i * i)) {
return 2;
}
}
return 3;
}
private boolean isPerfectSquare(int x) {
int sqrt = (int) Math.sqrt(x);
return sqrt * sqrt == x;
}
}
|
这种完全背包问题,322.零钱兑换也是相似的解法
41 缺失的第一个正数
给你一个未排序的整数数组,请你找出其中没有出现的最小的正整数。
输入:nums = [1,2,0]
输出:3
输入:nums = [3,4,-1,1]
输出:2
输入:nums = [7,8,9,11,12]
输出:1
思路
朴素浅显的思路是,遍历数组,依次将每个数加入HashSet。完成后,遍历HashSet,找到最小的正整数。
时间复杂度是O(n),空间复杂度是O(n)。
但这样会有空间上的浪费,浪费一个hashset的空间。这样就可以自己依赖原本的数组,来记录每个数是否出现过,自己实现一个hashset。但是数组是覆盖整个int范围的,没办法进行特殊标记。
但题目要求的不是最小的数,而是最小的正整数。所以可以先过滤一遍,将所有负数和0都过滤掉,变为超出长度的数值。
然后再遍历数组,记录每个数是否出现,将对应下标的数字变为负数,表示已经出现过。
最后再遍历数组,找到第一个正数,该数的下标就是最小的正整数。
(提醒,由于0不考虑在内,所以下标映射要减一)
标签: 哈希表 数组 负数 最小正整数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
class Solution {
public int firstMissingPositive(int[] nums) {
int MAX = nums.length;
for(int i = 0;i<nums.length;i++) {
if(nums[i]<=0)nums[i]=MAX+1;
}
for(int i = 0;i<nums.length;i++) {
int temp = Math.abs(nums[i]);
if(temp <= MAX) nums[temp-1]= - Math.abs(nums[temp-1]);
}
for(int i = 0;i<nums.length;i++) {
if(nums[i]>0)return i+1;
}
return nums.length+1;
}
}
|
76. 最小覆盖子串
给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 “” 。
注意:如果 s 中存在这样的子串,我们保证它是唯一的答案。
示例 1:
输入:s = “ADOBECODEBANC”, t = “ABC”
输出:”BANC”
示例 2:
输入:s = “a”, t = “a”
输出:”a”
示例 3:
输入:s = “a”, t = “aa”
输出:”aa”
思路
暴力法:枚举子串,判断是否包含t的所有字符,时间复杂度是O(n^3),空间复杂度是O(1)。
滑动窗口法:一种更简单、剪枝后的暴力法。
4. 寻找两个正序数组的中位数
给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。
进阶:你能设计一个时间复杂度为 O(log (m+n)) 的算法解决此问题吗?
示例 1:
输入:nums1 = [1,3], nums2 = [2]
输出:2.00000
解释:合并数组 = [1,2,3] ,中位数 2
示例 2:
输入:nums1 = [1,2], nums2 = [3,4]
输出:2.50000
解释:合并数组 = [1,2,3,4] ,中位数 (2 + 3) / 2 = 2.5
示例 3:
输入:nums1 = [0,0], nums2 = [0,0]
输出:0.00000
思路
处理边界情况的地方非常多,需要考虑到各种边界情况!
多看、多验证、多思考!
1.二分 + kth元素
找第 k 小的数,可以用二分法,时间复杂度是 O(log(min(m,n)))。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| class Solution {
public double findMedianSortedArrays(int[] nums1, int[] nums2) {
int m = nums1.length, n = nums2.length;
int total = m + n;
if (total % 2 == 1) {
return findKth(nums1, 0, nums2, 0, (total + 1) / 2);
} else {
double left = findKth(nums1, 0, nums2, 0, total / 2);
double right = findKth(nums1, 0, nums2, 0, total / 2 + 1);
return (left + right) / 2.0;
}
}
private double findKth(int[] nums1, int i, int[] nums2, int j, int k) {
if (i >= nums1.length) return nums2[j + k - 1];
if (j >= nums2.length) return nums1[i + k - 1];
if (k == 1) return Math.min(nums1[i], nums2[j]);
int mid1 = (i + k/2 - 1 < nums1.length) ?
nums1[i + k/2 - 1] : Integer.MAX_VALUE;
int mid2 = (j + k/2 - 1 < nums2.length) ?
nums2[j + k/2 - 1] : Integer.MAX_VALUE;
if (mid1 < mid2) {
return findKth(nums1, i + k/2, nums2, j, k - k/2);
} else {
return findKth(nums1, i, nums2, j + k/2, k - k/2);
}
}
}
|
2.分割数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| class Solution {
public double findMedianSortedArrays(int[] nums1, int[] nums2) {
if (nums1.length > nums2.length) {
return findMedianSortedArrays(nums2, nums1);
}
int m = nums1.length, n = nums2.length;
int totalLeft = (m + n + 1) / 2;
int left = 0, right = m;
while (left < right) {
int i = left + (right - left + 1) / 2;
int j = totalLeft - i;
if (nums1[i - 1] > nums2[j]) {
right = i - 1;
} else {
left = i;
}
}
int i = left;
int j = totalLeft - i;
int nums1LeftMax = (i == 0) ? Integer.MIN_VALUE : nums1[i - 1];
int nums1RightMin = (i == m) ? Integer.MAX_VALUE : nums1[i];
int nums2LeftMax = (j == 0) ? Integer.MIN_VALUE : nums2[j - 1];
int nums2RightMin = (j == n) ? Integer.MAX_VALUE : nums2[j];
if ((m + n) % 2 == 1) {
return Math.max(nums1LeftMax, nums2LeftMax);
} else {
return (Math.max(nums1LeftMax, nums2LeftMax) +
Math.min(nums1RightMin, nums2RightMin)) / 2.0;
}
}
}
|